# 前言
Google 的搜索引擎本身就是世界最大的網路爬蟲之一,無時無刻都在收集資料,但卻不喜歡別人爬走它的資料,用了自家開發的 reCAPTCHA 來保護自己。
提升自動化程度可以說是多數軟體工程師的目標,大家都想躺著賺錢,資安工程師也不例外,而 reCAPTCHA 可以說是 Google Hacking 自動化時會遇到的最大障礙,在嘗試了多種方法後決定寫篇文章記錄一下最後成功的方法,分享下各自的優缺點後加上主觀評分。
# Google Hacking 簡介
Google Hacking 簡單來說就是駭客利用 Google Search 來收集攻擊所需要的資料,最常見的就是利用進階搜索語法來找出敏感或非公開資訊,細講的話可以寫一整篇文章,下面提供一個簡單的 Google Hacking 範例,此範例能快速找出不設防的網路錄影機,找到後人人都可以駭進去。
範例 : intext:"powered by webcamXP 5"
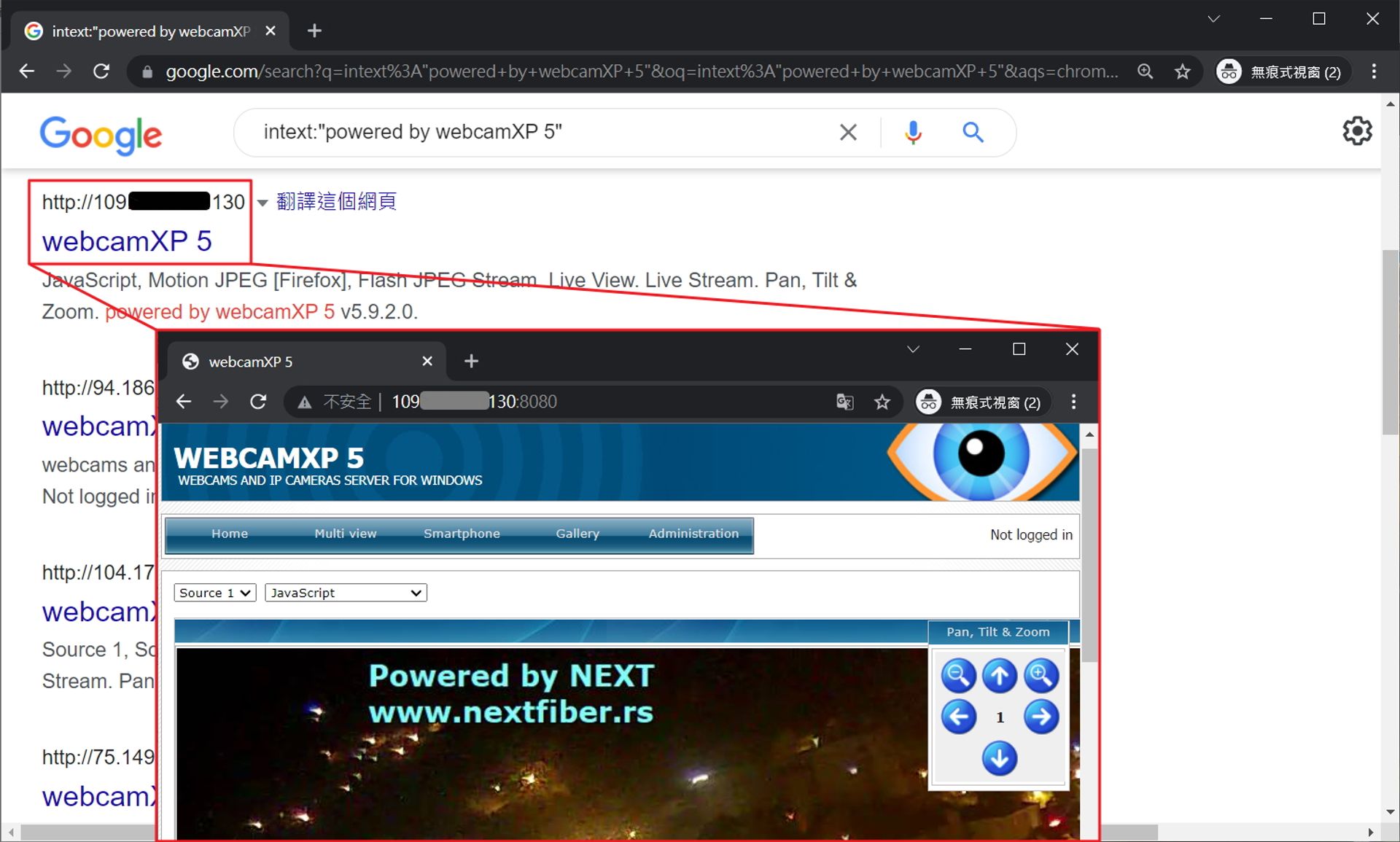
# reCAPTCHA 簡介
Google 會記錄使用者搜索的內容與瀏覽器上的資訊,當背後的 AI 藉由這些紀錄判斷當前使用者可能是自動化程式時,就會啟動 reCAPTCHA 驗證機制,跳出如下圖的視窗,需要通過測試 Google 才會進行這次搜索。
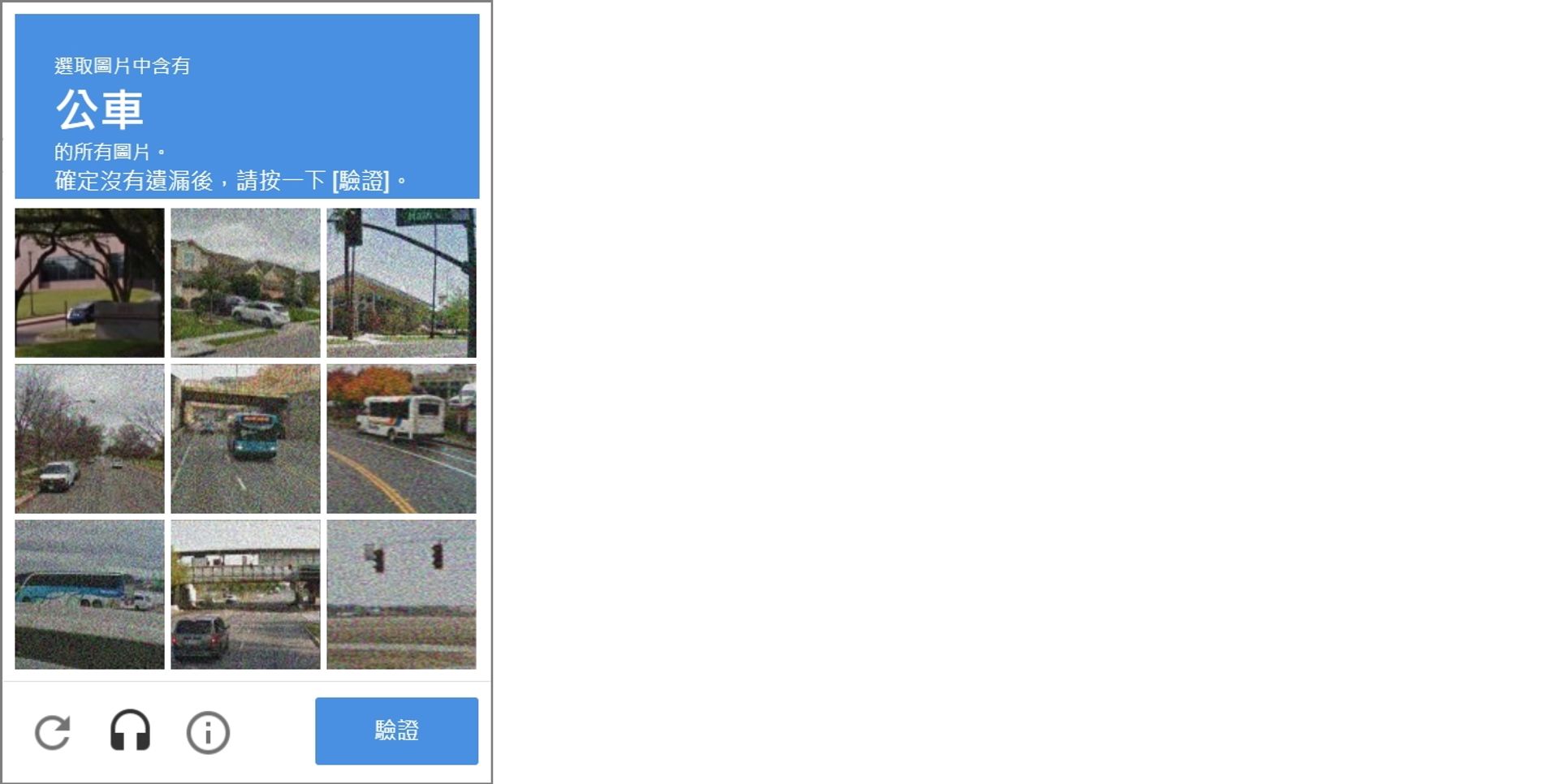
reCAPTCHA 最早會出對人簡單但對機器來說困難的問題,並藉回答的結果來分辨使用者是人還機器,後來隨著 Google AI 越來越強大,大多數狀況下已經可以只用瀏覽器上的資訊判斷是否為真人,所以後期的版本只要打個勾就可以放行,高度懷疑不是真人時才會請你做題目,很多網站上都可以看到下圖。

# 被 reCAPTCHA 擋了怎麼辦 ?
如果不想被 Google 的 reCAPTCHA 檔住,最簡單而且最穩妥方法是透過 Google 提供的 API 來進行搜索,但是每天只有 100 次的免費查詢額度,之後每 1000 次查詢要付 5 美元。如果跟我一樣不打算在測試階段就噴錢,或是預算不充足的話就需要多了解一下後面要介紹的解決方案。
爬站時不管是資安人員還是駭客都想繞過 reCAPTCHA,但背後有機器學習導致規則不斷變化,在加上本身不斷改版,所以不少網住文章上的繞過方法都已經失效,這邊分享 3 個經過驗證,至少在當前版本可行的繞過方法。
# 解決方案 1 : 偽裝
偽裝成一般人使用搜索功能,避免出現 reCAPTCHA,偽裝的話有很多細節,但最直接影響 reCAPTCHA 出現的有 2 點。
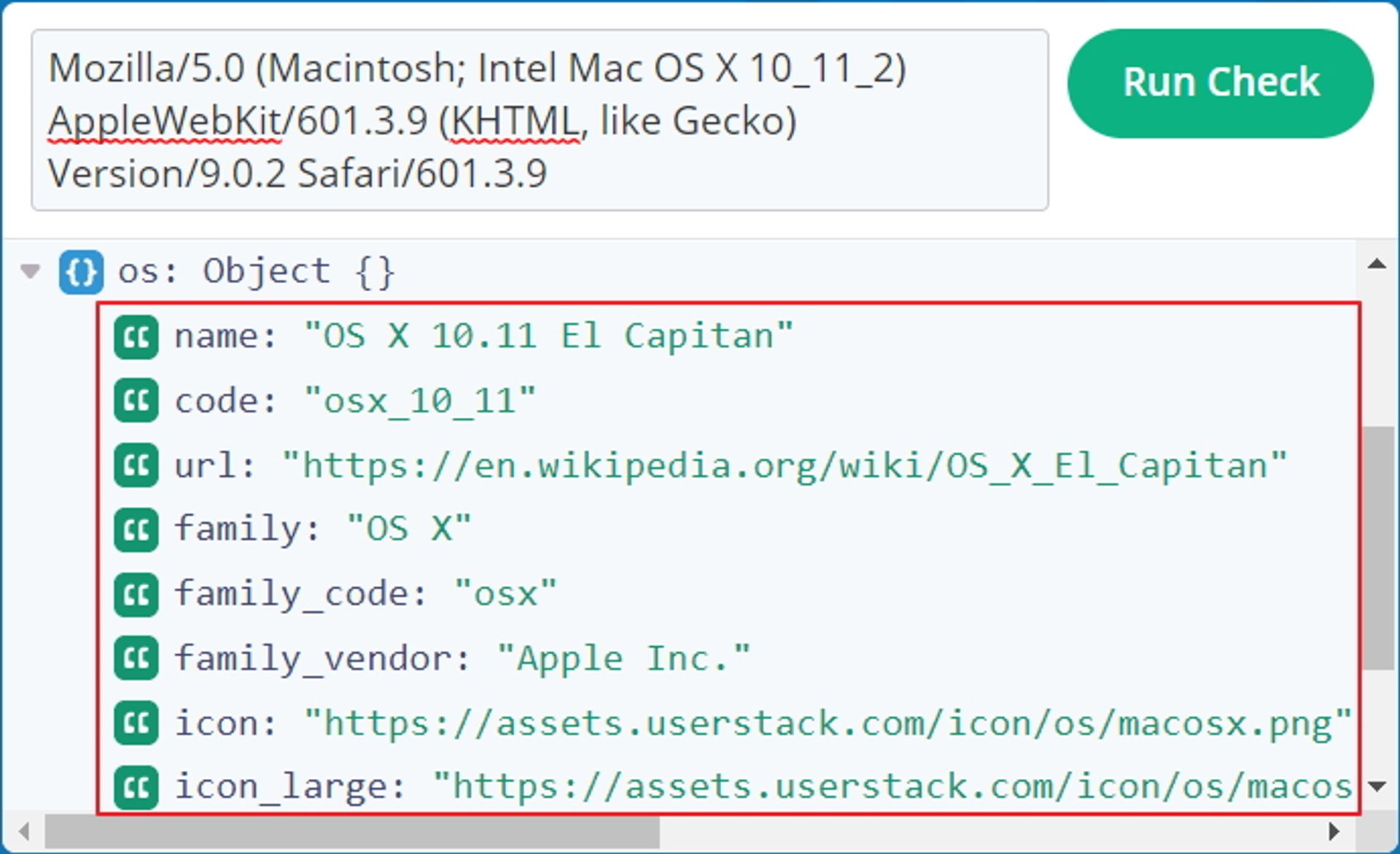
設定 User-Agent 偽裝成常見的設備:
只要將 User-Agent 的值改的跟下方範例一樣,網站會認為連進來的人用的是 Mac OS,如果從來源不明的裝置送請求跳出 reCAPTCHA 的機會將大幅提升,很明顯 Google 對從 Mac 或 Windows 等常見設備的請求檢查較寬鬆。Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9設定好 User-Agent 後可以到 userstack.com 這個網站來檢查偽冒有沒有成功,成功會如下圖。
避免短時間內發送大量或重複的請求:
即使裝的在像一般人發的請求,短時間內發太多次的話還是會被發現,重複太多次也一樣,Google 可以很容易從這些資訊猜出送請求的是自動化程式。
# 解決方案 2 : 正面對決
模仿一般人去回答 reCAPTCHA 的問題,但針對 reCAPTCHA 做出一套影像辨識系統非常麻煩,有一個取巧的方法是利用盲人輔助功能,讓回答難度從影像辨識降低到語音辨識,降到語音辨識後甚至可以讓 Google Speech 來對付 Google reCAPTCHA。
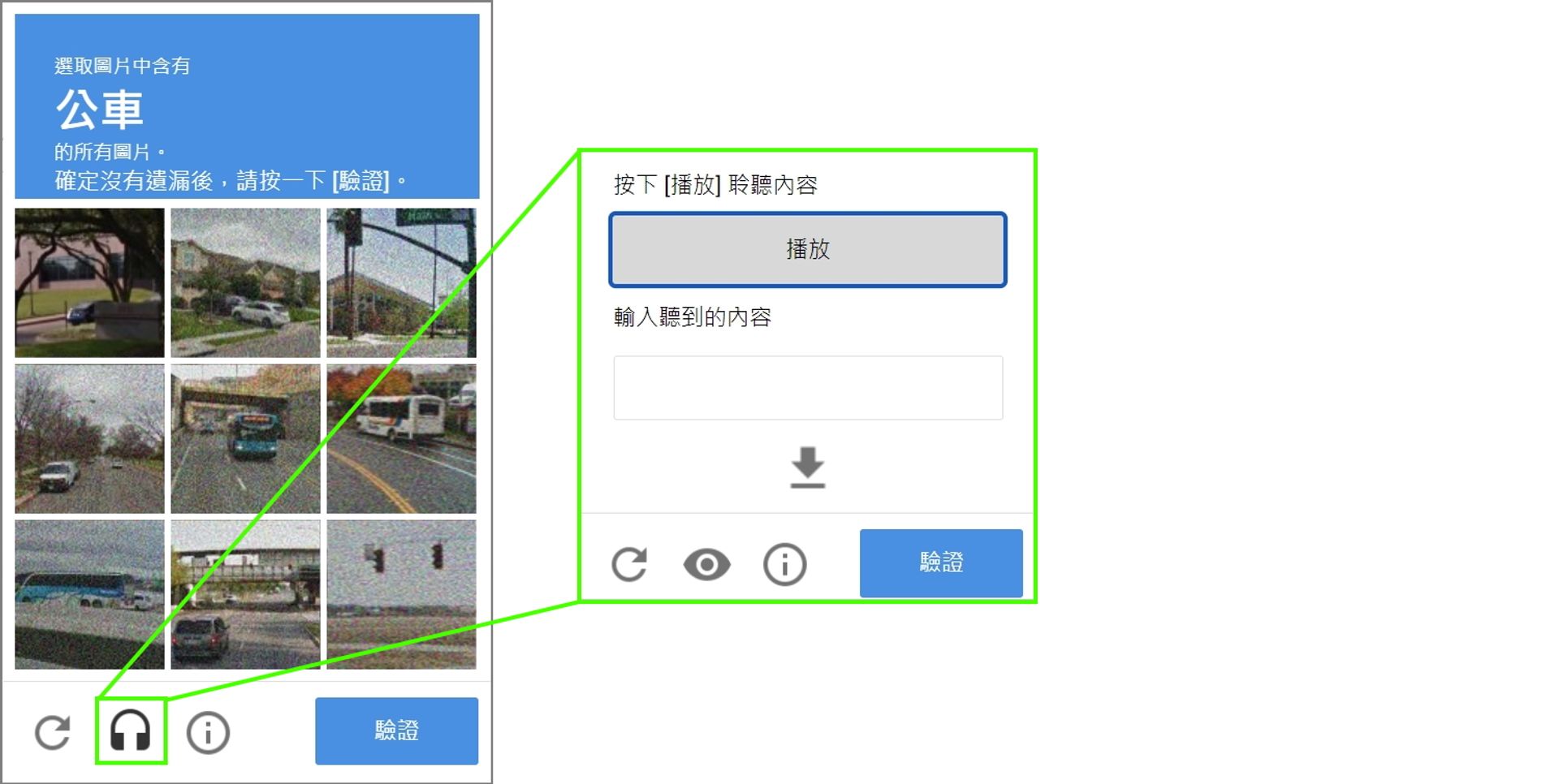
自動化測試時用的是 Python 的 SpeechRecognition 模組,利用模組中的 recognixe_google() 去呼叫 Google 語音辨識 API,讓 Google 語音辨識解決 Google reCAPTCHA 出的題目。
# 解決方案 3 : 換引擎
找其他沒有 reCAPTCHA 的搜索引擎來用,這邊實測微軟的旗下的 Bing 沒有任何搜索限制 ~
Bing 的搜索規則跟 Google 大同小異,這邊列一些覺得比較實用的規則給大家參考,紅字的是 Bing 才有 Google 沒有的規則,詳細規則可點連結看官方文件,這邊就不逐一介紹。
https://help.bing.microsoft.com/#apex/bing/en-US/10001/-1
| 規則 | 功能 |
|---|---|
| contains | 只搜索包含指定文件類型的鏈接的網站 |
| filetype | 僅返回以指定文件類型創建的網頁 |
| ip | 查找託管在特定 IP 地址的網站 |
| language | 返回指定語言的網頁 |
| location | 返回特定國家或地區的網頁 |
| url | 檢查列出的域或網址是否位於 Bing 索引中 |
| inanchor | 網頁元素查詢,含特定定位標記的網頁 |
| inbody | 網頁元素查詢,含特定正文的網頁 |
| intitle | 只搜索包含指定文件類型的鏈接的網站 |
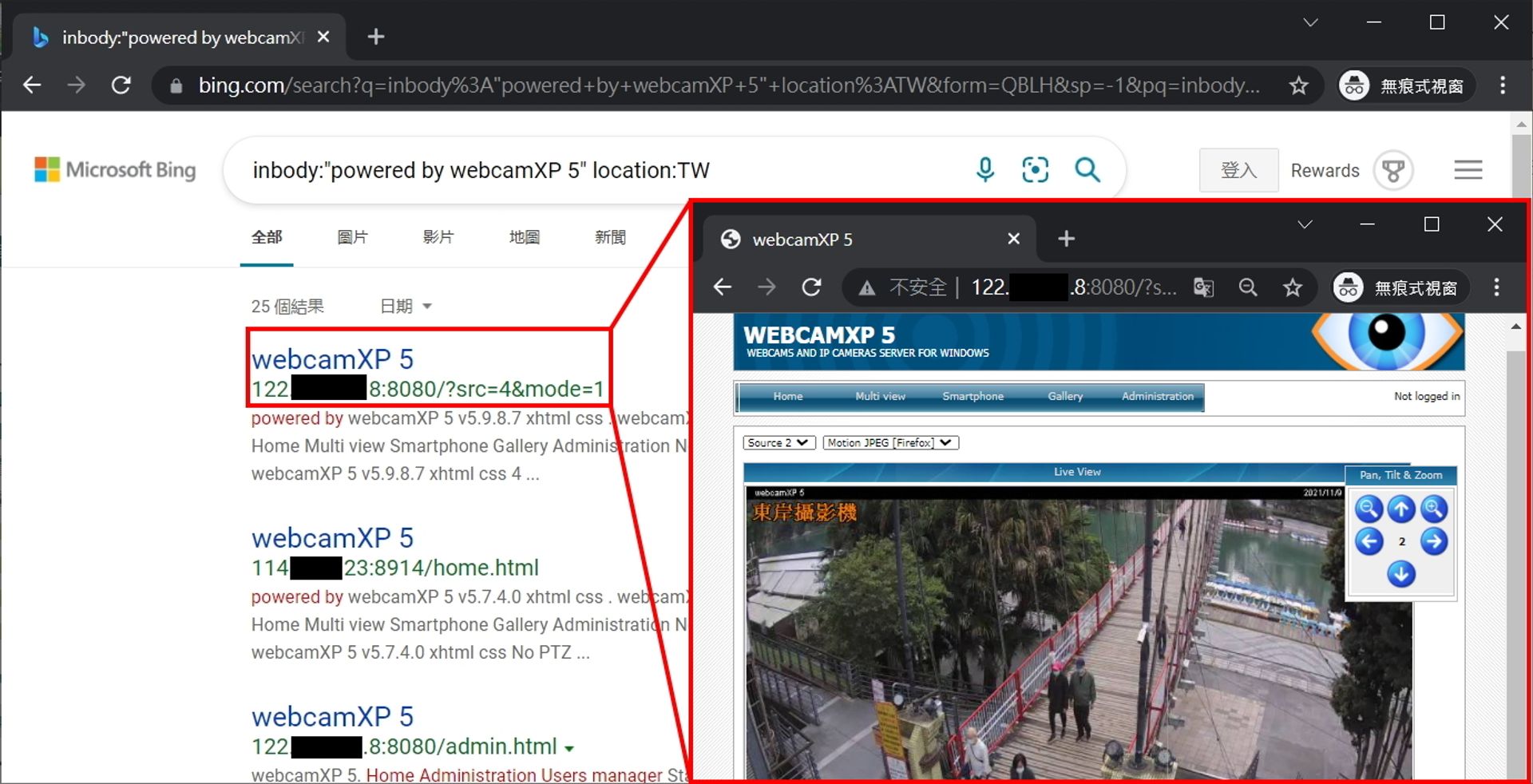
與前面一樣舉個找網路攝影機的範例,再加上地區限制為台灣,第一筆搜索結果就是台北碧潭的監視器
範例: inbody:"powered by webcamXP 5" location:TW
# 總結
最後討論一下各方法的優缺點,用適不適合自動化的角度來打分數,如果其他用途,可以看一下各方法的優缺點來決定,適合才是最重要的。
# 偽裝 : ★★★☆☆
- 優點: 設定簡單、可跳過驗證
- 缺點: 效率差、有機會被鎖
- 使用心得:
雖然只要靠設定就可以繞過驗證,但這方法最大的問題兩次搜索之間必須設定較長的等待時間來模仿一般人在使用搜索功能,這會導致自動化的效率有限,更換 IP 或者其他設定能降低被發現的機會,但搜索頻率高到一定程度還是會被抓到,而一但被判斷是自動化程式接下來一天都會跳出跳出 reCAPTCHA 驗證頁面。
# 正面對決 : ★★☆☆☆
- 優點: 穩定
- 缺點: 有次數上限、驗證複雜
- 使用心得:
因為不用擔心像前一個方法跳出驗證就導致服務中斷,比起來穩定的多,可惜的是語音辨識多使用幾次後 Google 背後的 AI 會開始懷疑來源是自動化程式,一旦懷疑就會禁用語音驗證的功能,這時候就不能再用 Google Speech 來對付 reCAPTCHA 了。
# 換引擎 : ★★★★☆
- 優點: 沒有 reCAPTCHA 限制
- 缺點: 部分結果被過濾
- 使用心得:
沒有限制後要自動化容易多了,不會綁手綁腳,唯一可惜的地方是 Bing 會過濾掉一些 Microsoft 認為重複或不重要的結果,Google 雖然預設也會過濾但可選擇顯示所有結果,很可惜 Bing 沒有提供這個選項,導致有機會漏掉一些資料,如果可以看到所有資料肯定給 5 顆星。
前面為快速說明原理挑了一些簡單易懂的攻擊來示範,實際上還有更多更進階的用法,如果閱覽數量夠多,之後會再加開一篇分享一些更進階的用法與經典案例,有任何資安方面相關的問題都歡迎留言討論,或者直接到 Cymetrics 尋求協助。
标签
推荐
Discussion(login required)