布隆过滤器(英语:Bloom Filter)是 1970 年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。主要用于判断一个元素是否在一个集合中。
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,空间效率和查询时间都远远超过一般的算法,但是缺点是其返回的结果是概率性的,而不是确切的。
# 实现原理
当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点(offset),把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
简单来说就是准备一个长度为m的位数组并初始化所有元素为 0,用 k 个散列函数对元素进行 k 次散列运算跟 len (m) 取余得到 k 个位置并将m中对应位置设置为 1。
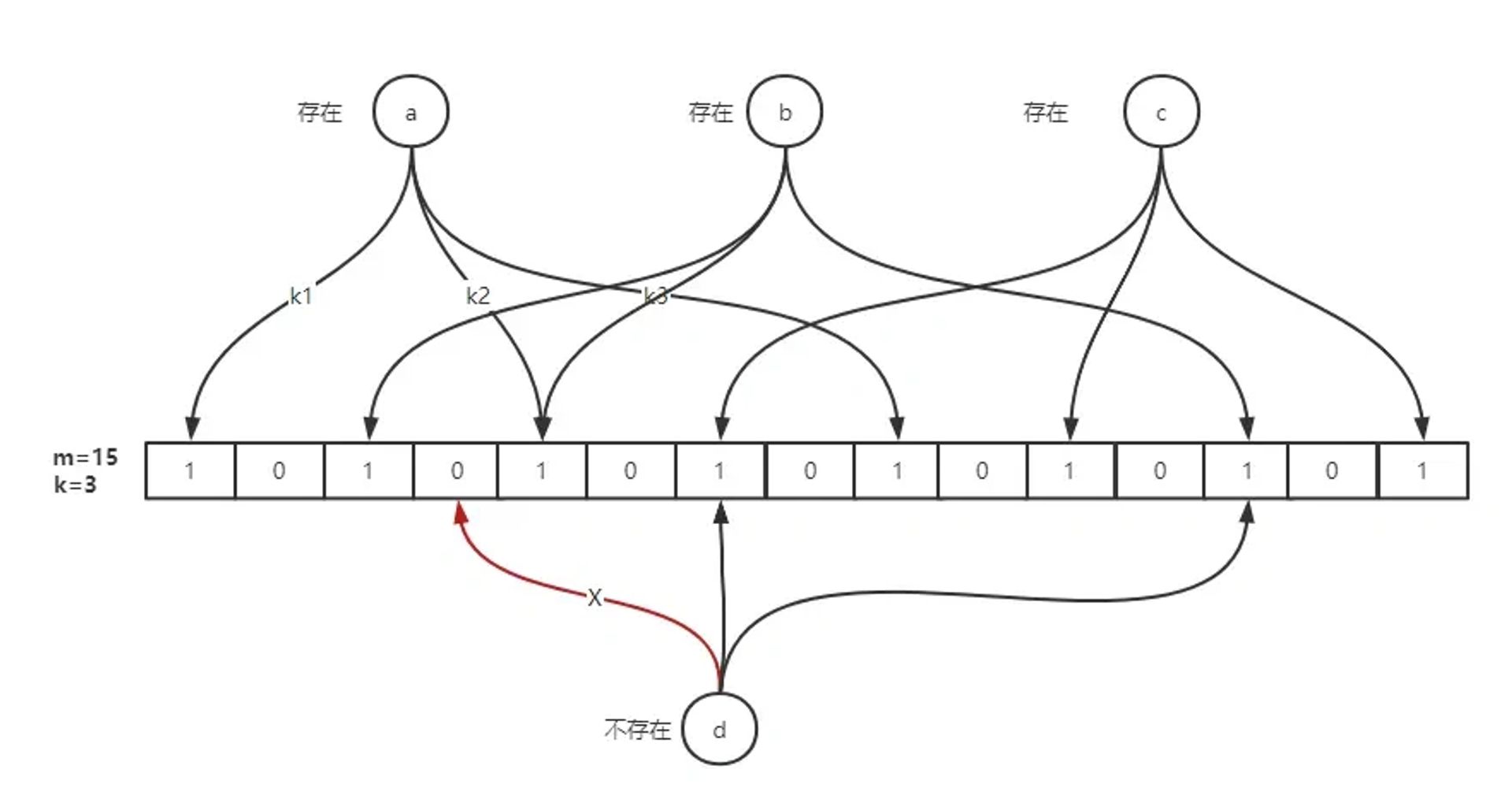
为什么会存在有不确定的情况呢?这里举一个简单的例子:假设现在有一个 8 bits 的二进制空间作为布隆过滤器,然后我们插入3和5这两个十进制数,哈希函数就选取简单的十进制转二进制,即插入 011 和 101,此时二进制空间的数据则为 00000111。
如果此时我们在布隆过滤器中检索3和5两个十进制数,则可以认为他们可能存在。检索十进制数9,对应二进制为1001,则判定为不存在,这个结果是必然的。但如果我们检索7这个十进制数,由于它的二进制表示为0111,因此会被误判为存在。所以才会出现上述的规则,而且随着插入元素数量的增加,出现误判的概率也会上升,因此布隆过滤器不适用于对精确度要求高的应用场合。
# 布隆过滤器添加元素
- 将要添加的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 将这k个位置设为1
# 布隆过滤器查询元素
- 将要查询的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 如果k个位置有一个为0,则肯定不在集合中
- 如果k个位置全部为1,则可能在集合中
# 优缺点
# 布隆过滤器的优点:
- 时间复杂度低,增加和查询元素的时间复杂为O(N),(N为哈希函数的个数,通常情况比较小)
- 保密性强,布隆过滤器不存储元素本身
- 存储空间小,如果允许存在一定的误判,布隆过滤器是非常节省空间的(相比其他数据结构如Set集合)
# 布隆过滤器的缺点:
- 有点一定的误判率,但是可以通过调整参数来降低
- 无法获取元素本身
- 很难删除元素
# 应用场景
- 原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中?解决办法一:将10亿个号码存入数据库中,进行数据库查询,准确性有了,但是速度会比较慢。解决办法二:将10亿号码放入内存中,比如Redis缓存中,这里我们算一下占用内存大小:10亿*8字节=8GB,通过内存查询,准确性和速度都有了,但是大约8gb的内存空间,挺浪费内存空间的
- 接触过爬虫的,应该有这么一个需求,需要爬虫的网站千千万万,对于一个新的网站url,我们如何判断这个url我们是否已经爬过了?解决办法还是上面的两种,很显然,都不太好。
- 数据库防止穿库。 Google Bigtable,HBase 和 Cassandra 以及 Postgresql 使用BloomFilter来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会大大提高数据库查询操作的性能
- 业务场景中判断用户是否阅读过某视频或文章,比如抖音或头条,当然会导致一定的误判,但不会让用户看到重复的内容。
- 缓存宕机、缓存击穿场景,一般判断用户是否在缓存中,如果在则直接返回结果,不在则查询db,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查询到,则穿透到db。如果不在布隆器中,则直接返回
- WEB拦截器,如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中。可以提高缓存命中率。Squid 网页代理缓存服务器在 cache digests 中就使用了布隆过滤器。Google Chrome浏览器使用了布隆过滤器加速安全浏览服务
- Venti 文档存储系统也采用布隆过滤器来检测先前存储的数据
- SPIN 模型检测器也使用布隆过滤器在大规模验证问题时跟踪可达状态空间
- 字处理软件中,需要检查一个英语单词是否拼写正确
- 在FBI,一个嫌疑人的名字是否已经在嫌疑名单上
- 黑名单过滤
- 同理还有垃圾邮箱的过滤。
- 手机号是否重复注册
- 用户是否参与过某秒杀活动
- 伪造请求大量id查询不存在的记录,此时缓存未命中,如何避免缓存穿透。那么对于类似这种,大数据量集合,如何准确快速的判断某个数据是否在大数据量集合中,并且不占用内存,就是布隆过滤器的典型应用场景
# 具体实现
# guava布隆过滤器
- 参看BloomFilter,适合于单机环境
# redis布隆过滤器
- 参看redisson的RBloomFilter
# References
- https://segmentfault.com/a/1190000024566947
- https://blog.51cto.com/zhangxueliang/2969274
- https://en.wikipedia.org/wiki/Bloom_filter
标签
推荐
Discussion(login required)